编译前所注意事项:
首先,尽可能阅读官网编译文档 Building Apache Spark
源码下载推荐git clone 或者 wget 。
编译前确保网络良好。
下载所需要的软件(注意版本)
· Spark-2.4.2.tgz
· Hadoop-2.7.6
· Scala-2.11.12
· jdk1.8.0_191
· apache-maven-3.6.x
· git
注意:其中spark是源码,其他是可运行包
解压安装并配置环境变量(过程略)
配置完,注意测试。其中,maven配置本地库,镜像地址设置为阿里云地址。1
2
3
4 创建本地仓库文件夹
mkdir ~/maven_repo
修改settings.xml文件
vim $MAVEN_HOME/conf/settings.xml
部分代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ${user.home}/.m2/repository
<localRepository>/path/to/local/repo</localRepository>
-->
<localRepository>/home/max/maven_repo</localRepository>
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*,!cloudera</mirrorOf>
<name>Nexus aliyun</name>
<url>
http://maven.aliyun.com/nexus/content/groups/public
</url>
</mirror>
修改脚本make-distribution.sh
编译不使用mvn这个命令,直接用make-distribution.sh脚本,但是需要修改该脚本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29spark-2.4.2文件夹下
vim ./dev/make-distribution.sh
将这些行注释掉 此处为最佳实践,为的是通过指定版本号减少编译时间
VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null\
| grep -v "INFO"\
| grep -v "WARNING"\
| tail -n 1)
SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\
| grep -v "INFO"\
| grep -v "WARNING"\
| tail -n 1)
SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
| grep -v "INFO"\
| grep -v "WARNING"\
| tail -n 1)
SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
| grep -v "INFO"\
| grep -v "WARNING"\
| fgrep --count "<id>hive</id>";\
# Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
# because we use "set -o pipefail"
echo -n)
#添加一下参数,注意,版本号要对应自己想要的生产环境
VERSION=2.4.2
SCALA_VERSION=2.11
SPARK_HADOOP_VERSION=hadoop-2.6.0-cdh5.14.0
SPARK_HIVE=1
修改源码包spark-2.4.2下的pom.xml
1 | <repositories> |
开始编译
1 | ./dev/make-distribution.sh \ |
编译大概需要半小时以上,耐心等待就行。编译过程中如果报错,一般有error字样。
出现以下字样,代表编译完成: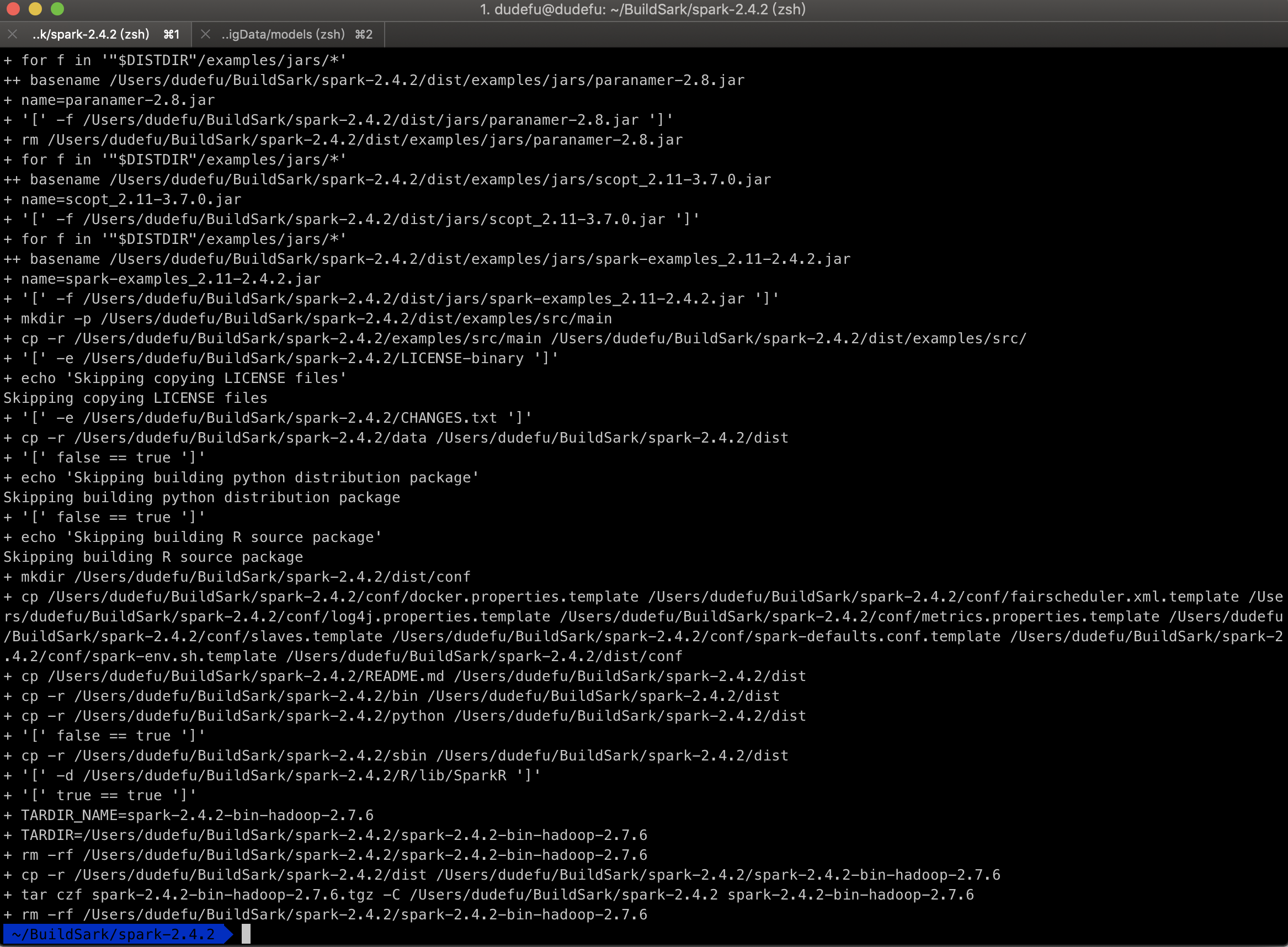
编译后包所在位置,源码包spark-2.4.2根目录下:
至此,编译完!